
Tech
5 Key Trends Shaping Modern IT Management
Modern IT management is evolving rapidly, driven by a new wave of technologies and operational strategies. Keeping pace with these changes is not just a competitive advantage but a necessity for any organization looking to thrive in a digital-first era. Forward-thinking companies like Design Data are already adapting to these seismic shifts, reimagining their IT infrastructures and practices. By understanding and acting on emerging trends, IT leaders can position their organizations for efficiency, resilience, and strategic growth.
From artificial intelligence to sustainability, today’s IT environment is characterized by complexity and unprecedented possibilities. The effective fusion of human ingenuity and intelligent automation now sets the stage for innovative approaches to cybersecurity, infrastructure planning, and collaborative work. As the pursuit of business agility and digital transformation accelerates, the importance of proactive IT management cannot be overstated.
AI Integration in IT Operations
The adoption of artificial intelligence marks one of the most significant shifts in IT operations today. AI-driven tools automate repetitive workflows, enabling IT departments to redirect resources toward innovation and higher-level problem-solving. Predictive analytics powered by machine learning identifies system vulnerabilities before they can cause disruptions, and intelligent monitoring solutions can boost uptime and overall reliability. According to ZDNet, businesses implementing AI in their IT operations often experience substantial improvements in both cost efficiency and service quality. Forward-minded organizations are investing in these advanced technologies to streamline incident response, optimize infrastructure, and unlock real-time, actionable insights from vast quantities of operational data.
Further, the role of AI extends beyond internal operations. Customer support and user experience have also been transformed through intelligent chatbots, self-healing systems, and dynamic user interfaces. This evolution fosters a culture of constant improvement where technology automatically adapts to changing business requirements. The efficiency gains and improved operational accuracy resulting from AI adoption provide a clear competitive edge.
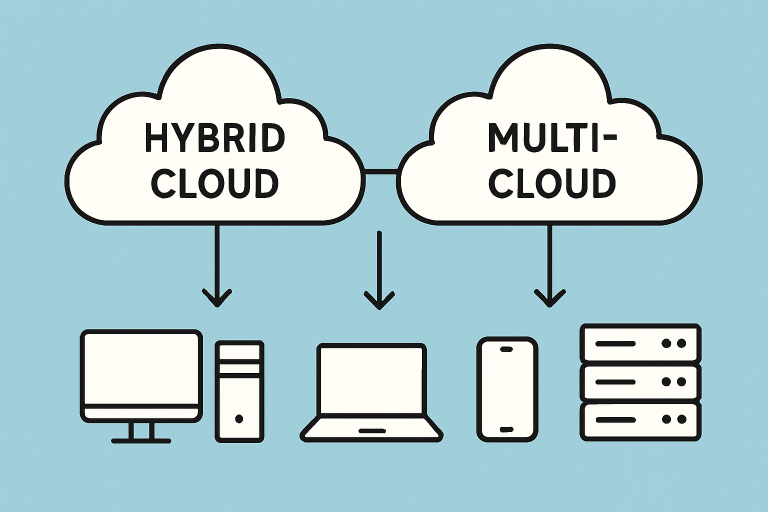
Adoption of Hybrid and Multi-Cloud Strategies
Cloud computing strategies have matured significantly in recent years. Rather than relying on a single provider or infrastructure, organizations now leverage a blend of private and public clouds for maximum flexibility and cost-effectiveness. A hybrid and multi-cloud approach allows businesses to choose the optimal environment for different workloads, while also reducing vendor dependency and providing additional layers of redundancy. This method is ideally suited to organizations with diverse application portfolios, regulatory requirements, or high-availability needs. Leading technology companies are increasingly touting the benefits of seamless cloud integration for operational agility and disaster recovery.
According to CIO.com, the move to hybrid and multi-cloud environments helps organizations manage costs, ensure business continuity, and deliver innovative services faster. These strategies give IT teams more granular control over data locality, compliance, and performance, thus enabling faster responses to fluctuating demands and regulatory shifts.
Implementation of Zero-Trust Security Frameworks
The complexity and severity of cyber threats continue to escalate, rendering perimeter-based security models obsolete. Zero-trust security frameworks operate on the principle that organizations should not automatically trust any internal or external entity. Instead, continuous verification is required for every access request, regardless of the source. Identity and device authentication, least-privilege policies, and comprehensive monitoring form the backbone of this approach. As organizations adopt hybrid and multi-cloud models, zero-trust provides a robust foundation for safeguarding sensitive data and critical assets.
Zero-trust architectures are proving vital for defending against ransomware, insider threats, and phishing attacks. The U.S. Cybersecurity and Infrastructure Security Agency (CISA) strongly advocates the widespread adoption of zero-trust principles, highlighting their ability to reduce the attack surface drastically and swiftly contain breaches. As regulatory requirements grow ever more stringent, this approach enhances compliance and fosters a proactive security culture.
Supporting Remote and Hybrid Work Environments
Remote and hybrid work models are firmly embedded in the modern business landscape. IT leaders are under pressure to deliver seamless digital experiences for distributed teams while ensuring secure access to organizational resources without compromising productivity or agility. Robust collaboration platforms, virtual desktops, and advanced endpoint management tools are now prerequisites for success in this environment. Indeed, enabling a productive remote workforce extends beyond connectivity to encompass user experience, cyber hygiene, and change management.
To ensure business continuity and employee engagement, IT departments must deploy flexible solutions that support device diversity, network fluctuations, and asynchronous collaboration while maintaining robust security controls. As reported by Forbes, successful organizations are those that can deliver the right mix of tools, policies, and training that allows employees to excel from anywhere while safeguarding sensitive information.
Focus on Sustainability and Green IT
Sustainability is rising rapidly on the IT management agenda. With growing concerns over climate change and regulatory scrutiny, organizations are embracing green IT practices to reduce their environmental footprint and cut operational costs. Data center efficiency, virtualization, and cloud-native solutions are at the heart of this movement. The transition to paperless offices and the use of renewable energy for powering infrastructure are further examples of sustainable innovation in action.
Green IT initiatives not only respond to societal expectations but also deliver measurable benefits, including energy savings and improved brand reputation. As tech giants and startups alike join the push for carbon neutrality, sustainability is set to remain a key consideration in IT planning. According to The Verge, many of the world’s leading tech firms are already committing to clean energy and advanced recycling techniques to curb emissions across their global operations.
Modern IT management is fundamentally about anticipating change and aligning technology strategy with broader business goals. By embracing AI-driven automation, adopting versatile cloud strategies, bolstering security with zero-trust frameworks, supporting remote work, and prioritizing eco-friendly practices, organizations can not only overcome the challenges of the digital age but also turn them into lasting opportunities.

Modern technology evolves at lightning speed, introducing new concepts that reshape how individuals and businesses interact with digital systems. One such emerging term gaining attention is VAÇPR. While still developing, VAÇPR is increasingly associated with innovation, automation, and intelligent connectivity. This article explores what VAÇPR represents, how it works, and why it could shape the future of modern technology.
What Is VAÇPR?
VAÇPR is commonly described as a next-generation technological framework that blends advanced computing, predictive analytics, and adaptive systems. It is often linked to technologies like artificial intelligence, cloud computing, and data-driven automation.
At its core, VAÇPR focuses on:
- Intelligent decision-making
- Real-time data processing
- Scalable digital infrastructure
- Automation of complex workflows
- Enhanced user personalization
This combination makes VAÇPR a promising concept for industries looking to improve efficiency and innovation.
Key Features of VAÇPR
1. Intelligent Automation
VAÇPR emphasizes automation powered by intelligent algorithms. This allows systems to learn from data and optimize operations without constant human intervention.
2. Adaptive Architecture
Unlike traditional rigid systems, VAÇPR frameworks adapt dynamically. They can evolve based on user behavior, system performance, and emerging requirements.
3. Predictive Analytics
VAÇPR uses predictive modeling to anticipate trends, user needs, and potential system issues. This helps organizations make proactive decisions.
4. Seamless Integration
One of the most attractive aspects of VAÇPR is its ability to integrate with existing tools and platforms. This reduces implementation costs and improves flexibility.
5. Enhanced Security
Modern frameworks must prioritize security. VAÇPR incorporates advanced monitoring and risk detection to protect sensitive data.
How VAÇPR Is Transforming Modern Technology
VAÇPR is not limited to one sector. Its flexible nature makes it useful across multiple industries:
1. Business & Enterprise Solutions
Companies can use VAÇPR to automate workflows, improve customer insights, and optimize resource management.
2. Healthcare Innovation
Predictive analytics in VAÇPR can assist in early diagnosis, patient monitoring, and personalized treatment recommendations.
3. Smart Cities
VAÇPR can support traffic optimization, energy management, and intelligent infrastructure planning.
4. Finance & FinTech
Banks and financial platforms can leverage VA ÇPR for fraud detection, risk assessment, and automated investment strategies.
5. Education Technology
Adaptive learning platforms powered by VA ÇPR can personalize content for students and improve learning outcomes.
Benefits of VAÇPR in Modern Systems
- Faster decision-making
- Reduced operational costs
- Improved system efficiency
- Better user experiences
- Enhanced scalability
- Data-driven insights
These advantages explain why organizations are exploring VA ÇPR as part of their digital transformation strategy.
Challenges and Considerations
While VA ÇPR offers many benefits, there are also challenges:
- Implementation complexity
- Data privacy concerns
- Skill requirements for management
- Integration with legacy systems
Proper planning and strategy are essential for successful adoption.
The Future of VAÇPR
The future of VA ÇPR looks promising. As technologies like AI, IoT, and edge computing continue to evolve, VA ÇPR may become a central framework for smart digital ecosystems.
Potential future developments include:
- Fully autonomous business operations
- AI-driven infrastructure management
- Hyper-personalized digital experiences
- Intelligent cybersecurity systems
These advancements could redefine how technology supports everyday life.
Who Should Pay Attention to VAÇPR?
- Tech startups
- Digital transformation leaders
- Software developers
- Data scientists
- Enterprise decision-makers
- Innovation strategists
Anyone involved in modern technology development may benefit from understanding VA ÇPR.
Conclusion
VAÇPR represents a forward-looking approach to modern technology. By combining automation, predictive analytics, and adaptive systems, it has the potential to reshape industries and digital ecosystems. While still emerging, its impact could be significant for organizations aiming to stay competitive in a rapidly evolving technological landscape.
FAQ’s
What does VAÇPR stand for?
VA ÇPR is considered a conceptual framework representing adaptive, predictive, and intelligent technology systems.
Is VA ÇPR a real technology or a concept?
It is currently more of a conceptual framework but may evolve into defined technological standards.
How can businesses use VAÇPR?
Businesses can apply VA ÇPR principles to automate processes, analyze data, and improve decision-making.
Is VA ÇPR related to AI?
Yes, VAÇPR often integrates artificial intelligence and machine learning capabilities.
Why is VA ÇPR important for the future?
Because it focuses on automation, scalability, and intelligent systems that define next-generation technology.

Tracking your shipments has never been more important in today’s fast-paced world of online shopping. One tracking code that frequently appears in courier updates is LZ8948391235932AU. While it may look complex, understanding how to use it effectively ensures you stay informed about your package’s journey, from dispatch to delivery.
What Is LZ8948391235932AU?
LZ8948391235932AU is a tracking number typically used by international courier services, including postal and logistics companies. The format of this code indicates:
- “LZ” prefix – Usually denotes the type of service, often registered mail or international express.
- Numeric sequence – A unique identifier assigned to your package.
- “AU” suffix – Signifies the country of origin, in this case, Australia.
Each tracking number is unique, allowing both you and the courier to monitor the exact location and status of your parcel.
How to Track LZ8948391235932AU in Real Time
Tracking your shipment with LZ8948391235932AU is simple. Here’s how to do it:
1. Use the Official Courier Website
Most couriers provide a dedicated tracking page:
- Visit the official website of the courier (e.g., Australia Post or international partners).
- Locate the tracking tool.
- Enter LZ8948391235932AU in the search or tracking box.
- Click Track to see the latest updates.
2. Mobile Apps
Many logistics companies have mobile apps offering push notifications for updates. Enter your tracking code once, and you’ll receive alerts whenever your package changes status.
3. Third-Party Tracking Services
Websites like ParcelMonitor or 17track.net aggregate courier updates worldwide. Input LZ8948391235932AU, and you’ll get a consolidated timeline of your parcel’s journey.
Understanding Real-Time Status Updates
When tracking LZ8948391235932AU, you might encounter several status messages:
- Accepted at Origin – The package has been registered and is ready for dispatch.
- In Transit – The parcel is on the move, either domestically or internationally.
- Arrived at Sorting Facility – The package reached a logistics hub for processing.
- Customs Clearance – The parcel is undergoing checks by customs authorities.
- Out for Delivery – The courier is delivering the package to the specified address.
- Delivered – The package has successfully reached the recipient.
Knowing what these updates mean helps you anticipate delivery and address any potential issues quickly.
Tips for Smooth Tracking
- Check Early and Often – Real-time updates provide the best accuracy if you check frequently.
- Use Notifications – Enable SMS or app alerts to stay informed automatically.
- Confirm Details – Ensure your address and contact information are correct to prevent delays.
- Contact Customer Support – If updates seem stalled for an extended period, reach out to the courier with LZ8948391235932AU handy.
- Track Across Borders – For international shipments, track both the origin and destination country’s postal services for complete insight.
Common Issues & How to Solve Them
- Delayed Updates – Sometimes scanning delays occur. Wait 24-48 hours before contacting support.
- Customs Holds – International shipments may experience customs clearance delays; check for required documentation.
- Lost Packages – In rare cases, if a parcel shows no movement for several days, lodge a tracking inquiry with your courier.
FAQ’s
Q1: Can I track LZ8948391235932AU from my phone?
Yes, most courier websites and third-party apps allow full tracking via mobile devices.
Q2: How long does international shipping take with this code?
Delivery time varies depending on the origin, destination, and courier service. Typically, it ranges from 7–21 business days.
Q3: Is this tracking number unique?
Yes, LZ8948391235932AU is unique to a single parcel. No other package shares this identifier.
Q4: What does “customs clearance” mean?
It indicates that your package is being inspected by customs authorities to ensure it meets import regulations.
Q5: Can I request faster updates?
You can enable notifications via the courier’s app or third-party tracking services for real-time alerts.
Final Thoughts
Tracking LZ8948391235932AU doesn’t have to be confusing. By understanding the code, using official or third-party tracking tools, and interpreting status updates correctly, you can stay informed about your shipment every step of the way.

Introduction
Financial services are witnessing a seismic transformation as Artificial Intelligence (AI) becomes woven into their daily operations. Institutions are shifting toward AI-first operations to streamline processes, improve decision-making, and deliver more personalized solutions. With AI-driven systems now critical to staying competitive, many organizations are seeking advanced tools such as Ridgeline.AI to accelerate digital modernization and optimize service delivery across their business lines.
This wave of innovation is more than a fleeting trend: AI technologies have reached the core of financial services, helping teams extract insights from data, manage risk more effectively, and create unmatched customer experiences. The industry’s ongoing transformation shows how AI-first operations are rewriting the rules for efficiency, accuracy, and client satisfaction.
As AI becomes foundational to finance, decision-makers need to understand which use cases are delivering measurable impact and which strategies allow them to harness intelligent systems most effectively. With financial technology ecosystems expanding fast, including AI-powered credit assessment, risk analytics, and fraud detection, business leaders are rethinking what is possible in a digital-first era.
The following explores the leading ways AI is enabling finance teams to deliver better results for their organizations and customers. These solutions are not just addressing the legacy pain points but are also creating new opportunities for growth and differentiation across the sector.
Enhancing Fraud Detection and Security
Fraud prevention remains one of the foremost priorities for financial institutions worldwide, and AI is playing an increasingly critical role in this battle. By analyzing immense volumes of transaction and user behaviour data in real time, intelligent systems can spot anomalies that point to suspicious or fraudulent activity. This robust pattern recognition approach allows institutions to quickly flag and investigate outliers, effectively minimizing losses and improving customer trust.
For example, payment processors are now integrating multimodal AI systems that examine user context, historical transaction trends, and peripheral data. The resulting security upgrades not only curtail fraud but also significantly lower false positive rates that have traditionally been a source of friction for legitimate customers. As the cost of financial crime climbs annually, the need for such dynamic AI-powered solutions keeps growing. Major banks are also turning to emerging machine learning frameworks to further tighten security per directives and best practices highlighted by Forbes.
Revolutionizing Credit Assessment
Traditional credit scoring systems depend on static, limited data points, often creating barriers for individuals and businesses with unconventional financial backgrounds. AI shifts this paradigm by evaluating a broader range of structured and unstructured data, from transaction histories and mobile payments to social signals and behavioral spending patterns. This data-driven approach improves assessment accuracy, enhances risk prediction, and ultimately increases financial inclusion by extending credit to previously underserved customer segments.
With AI, lenders can go far beyond credit bureau reports and legacy scoring models. Automated systems can now bring millions of additional data records into the fold almost instantly, which means more reliable predictions of creditworthiness and a more level playing field for applicants. As more regulators encourage fairness and transparency in lending, AI-enabled credit models are poised to become a new benchmark.
Advancing Risk Management
Risk is an ever-present factor for financial institutions, encompassing everything from credit default and liquidity shortfalls to market shocks and regulatory shifts. Advanced AI models are transforming risk management methodologies by continuously analyzing vast pools of data, including market indicators, customer behaviors, and economic metrics. These systems spot potential risks much faster than humans can, enabling executives to make more precise and proactive decisions about their exposures and investment portfolios.
AI is now also being used to integrate emerging risks like climate change into core financial analysis, which is proving essential as stakeholders and regulators demand higher standards of sustainability. By supporting comprehensive scenario analysis and stress testing, AI-powered risk platforms allow financial organizations to better anticipate adverse events and minimize volatility in their results.
Personalizing Customer Experiences
Modern customers expect frictionless and highly personalized digital banking experiences. AI-powered platforms are meeting these demands by powering sophisticated virtual financial advisors who provide tailored guidance and manage common requests across web and mobile channels. Unlike early chatbots, these virtual agents use advanced natural language processing and machine learning to understand individualized goals, risk tolerances, and life events, staying one step ahead in meeting customer needs.
The result is a significant increase in customer satisfaction and loyalty, as intelligent systems can resolve queries faster and offer advice that aligns with each client’s financial journey. AI-driven personalization is enabling smaller institutions to deliver the level of service that was once only possible for the largest global banks, narrowing the customer experience gap across the industry.
Automating Data Processing and Financial Operations
One of the most impactful applications of AI in finance is the automation of time-consuming data processing and reporting tasks. Complex workflows such as invoice reconciliation, data entry, and financial close cycles can be managed more efficiently with AI-powered tools that accurately extract, validate, and categorize information from disparate documents. This has dramatically reduced operational errors and freed finance teams to focus on more strategic initiatives.
Organizations report that AI-driven automation can reduce task time from hours to minutes, with error rates dropping by up to 90 percent. By streamlining these essential operations, firms can react more quickly to market events and regulatory requests, improving overall agility and competitiveness.
Conclusion
The adoption of AI-first operations marks a foundational evolution in financial services. Banks, issuers, and fintechs that embrace intelligent systems are primed to unlock new efficiencies and deliver superior client outcomes. As AI technology continues to evolve, it will be those institutions that remain agile and forward-thinking who will capture the opportunities of tomorrow’s digital economy while effectively managing its risks.
-

 TOPIC6 months ago
TOPIC6 months agov4holt: Revolutionizing Digital Accessibility
-

 TOPIC8 months ago
TOPIC8 months agoAiyifan: The Digital Platform Transforming Access to Asian Entertainment
-

 TOPIC8 months ago
TOPIC8 months agoMolex 39850-0500: An In-Depth Overview of a Key Connector Component
-

 blog6 months ago
blog6 months agoBlack Sea Body Oil: A New Standard in Natural Skincare
-

 TOPIC6 months ago
TOPIC6 months agoMamuka Chinnavadu: An Exploration of Its Significance and Cultural Impact
-

 TOPIC8 months ago
TOPIC8 months agoManguonmienphi: Understanding the Concept and Its Impact
-

 TOPIC7 months ago
TOPIC7 months agoGessolini: Minimalist Aesthetic Rooted in Texture
-

 TOPIC8 months ago
TOPIC8 months agoDorothy Miles: Deaf Poet Who Shaped Sign Language